Sve više ličnih podataka u ChatGPT-u: Koliko su naši razgovori zaista privatni?
KomentariSve više ljudi svakodnevno koristi ChatGPT za najličnije stvari - od emocija i mentalnog zdravlja do finansijskih i profesionalnih problema. Istovremeno, na društvenim mrežama sve su učestalija upozorenja da ti razgovori možda i nisu toliko privatni koliko korisnici misle.
Tema emisije Van kocke na Euronews Srbija bila je upravo to - šta zapravo ostaje iza naših razgovora sa chatbotovima i šta da radimo ukoliko smo preterali i podelili, na primer, lična dokumenta ili osetljive podatke.
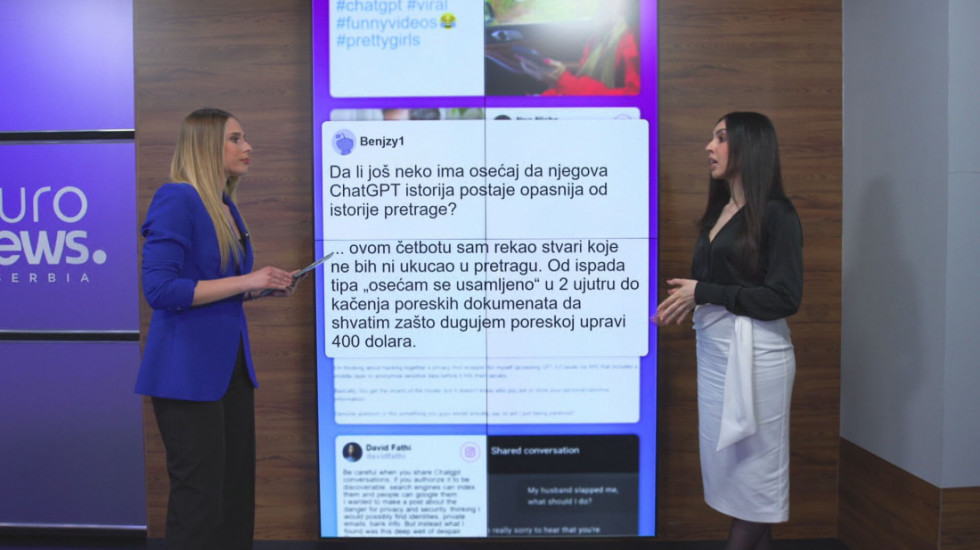
Na društvenim mrežama sve češće se pojavljuju objave koje upozoravaju na navodnu ugroženost privatnosti. Jedna objava sa Reddita postala je posebno viralna, gde korisnik navodi da ima osećaj da njegova ChatGPT istorija postaje "opasnija od istorije pretrage".
Kako tvrdi, sa chatbotom je delio sve - od emotivnih trenutaka poput "osećam se usamljeno u dva ujutru", do kačenja poreskih dokumenata kako bi razumeo zašto duguje 400 dolara Poreskoj upravi. Slični sadržaji mogu se videti i na TikToku, gde korisnici navode da im ne smeta ako neko vidi njihove poruke na društvenim mrežama, ali da bi ih zabrinulo otkrivanje ChatGPT istorije razgovora.
Upozorenja na mrežama su različita - od poruka poput "obrišite sve svoje ChatGPT razgovore pre nego što bude kasno", do tvrdnji da je privatnost "mit" i da veštačka inteligencija "špijunira korisnike". Saveti koji se dele na društvenim mrežama kreću se od redovnog brisanja istorije razgovora i memorije, do potpune suprotnosti - da "panika nije rešenje" i da se radi o preterivanju.
Slična zabrinutost pojavila se još prošle godine, kada je izvršni direktor OpenAI-ja Sem Altman govorio o tome da ne postoji potpuna poverljivost u razgovorima sa ChatGPT-om, za razliku od odnosa sa, na primer, terapeutom.
On je tada upozorio da ne postoji pravna zaštita koja bi garantovala potpunu privatnost, te da bi kompanija u određenim slučajevima mogla biti primorana da dostavi korisničke razgovore, na primer u sudskim postupcima.
Povezane vesti


Aleksandra Krstajić, konsultantkinja za sajber bezbednost na pitanje koliko je rizično deliti emotivne, intimne ili finansijske podatke sa chatbotovima, ističe da je ključni problem često u ponašanju samih korisnika.
Euronews Srbija
"Svakako je početna stavka upravo ponašanje korisnika. Suština odgovora krije se i u formulaciji samog korisnika - u pitanju su podaci koje on unosi. Ključna reč je osećaj, odnosno emotivni i psihološki aspekt koji donose nove tehnologije, jer gubimo osećaj da je naspram nas sistem", navodi ona.
Kako objašnjava, razgovor sa AI sistemima deluje prirodno, sa trenutnim odgovorima i često "primesama empatije", zbog čega korisnici stiču utisak da komuniciraju sa nekim ko im može biti prijatelj ili savetnik.
"Zaboravljamo da svaki upit, odnosno svaki podatak koji pošaljemo, ide na server gde se obrađuje kako bismo dobili odgovor", dodaje ona.
Da li smo dovoljno upozoreni na rizike?
Na pitanje da li su korisnici dovoljno upozoreni o načinu korišćenja podataka, Krstajić kaže da odgovor nije jednostavan.
"Pa i da i ne. Svaka platforma, kao i društvena mreža ili aplikacija, mora transparentno da navede načine obrade podataka i tipove podataka koji se prikupljaju", ističe ona.
Dodaje da je važno da korisnici razumeju i pravni okvir u kojem te kompanije posluju, kao i regulative koje važe u državama gde se nalaze i gde se nalaze njihovi korisnici.
Povezane vesti

Na pitanje šta uraditi ako su već podeljeni osetljivi podaci, Krstajić navodi da nema mesta panici.
"Prvi korak je da se revidiraju podešavanja na platformi - memorija, istorija razgovora i opcije učenja modela. Ukoliko se koristi nalog, važno je promeniti lozinke i koristiti jake lozinke, kao i višefaktorsku autentifikaciju", kaže ona.
Ipak, naglašava da je najbolja zaštita - prevencija.
Povezane vesti

"Najvažnije je filtriranje podataka koji se unose u sistem", dodaje.
Šta znači opcija "isključi treniranje modela"?
Objašnjavajući opciju isključivanja korišćenja podataka za treniranje AI modela, Krstajić kaže da to ne znači potpunu zaštitu privatnosti.
"Treniranje modela znači korišćenje velikih količina podataka kako bi se uočili obrasci i razvila jezička i matematička logika za generisanje odgovora", navodi ona.
Kako ističe, to ne znači da se korisnici direktno profilišu, već da se uče opšti obrasci jezika i komunikacije.
"Ako isključimo tu opciju, samo izbegavamo jednu svrhu korišćenja podataka, ali to ne znači da podaci ne postoje ili da se ne obrađuju - oni i dalje moraju proći kroz sisteme da bi odgovor bio generisan“, zaključuje ona.
Detaljnije pogledajte u videu iznad teksta.


















Komentari (0)